Introduction
LoLCATs proposes a way to create linear transformers. Instead of training an efficient transformer from scratch, this technique allows for 'linearizing' existing transformers by finding a kernel function that is effective in approximating the softmax function:
This approach reshapes the computation by multiplying the mapped K and V first, reducing the time complexity from
where D is the hidden dimension to
The idea behind diff transformer is that instead of using one set of q, k matrices to form the attention weights, it might be effective to use two q and k matrices and take a weighted difference. Using these two maps, it's possible to reduce the amount of weight for irrelevant tokens.
Idea
One of the things that I read in the LoLCATs paper was this idea of there being a lack of "spikiness" in the feature map. Around the same time, I read about Differential Transformers and how that was successful in making the attention map for traditional transformers sparser.
Linear attention can be written as follows:
Diff attention can be written as follows:
Naively, replacing the existing feature maps with "diff feature maps" would look something like this:
However, this can produce negative values. While this is acceptable when training a model from scratch, it hampers the approximation of the original attention map in the model being emulated. Therefore, we need to produce a reliably non-negative attention map:
While this formula ensures that the resultant attention map is non-negative, it also made it more difficult for me to normalize in a way that produces an attention map that sums to 1 in both the quadratic and linear forms.
This led to me switching over to a new approach that would ensure that the second map would have values that are stricly less than the first attention map:
This approach uses an element-wise multiplication of the second feature map on top of the old feature map. As a result, each element of the attention map is computed as follows:
It must be ensured that every variable is greater than zero, and that
which is easy to guarantee by coupling activation functions like ReLU and sigmoid.
Validating and Testing the Implementation
I validated this approach by implementing both linear and quadratic versions, comparing their results over random matrices. Similar to my previous blog post, I wrote a monkeypatch for the LlamaAttention forward pass method to include a step that would train my custom approaches for attention. After observing unusually low losses likely caused by my training configuration, I switched over to integrating my changes into the LoLCATs repository, restricting my changes to the training phase to avoid rewriting the cache mechanism for two attention maps.
Setup and Runs
To set up the model, I used mostly the same configuration as the existing LoLCATs reference implementation, but replaced the Llama-8b model with the Llama-1b model for faster performance.
The first few times I tried training the model, my loss was exploding after only a few iterations of decreasing loss.I resolved this by clipping gradient norms. However, after training the model, I observed performance degradation. I also tried a few furhter approaches to see
- Fix lambda to a certain value and train from there
- Fixing lambda to a specific value simplifies implementation and could reduce over-reliance on the original softmax attention map.
- Allow for additive attention maps
- Have the two attention maps be completely separate by using addition instead of subtraction. It is possible that having two unrelated attention maps may improve performance.
- Change the kind of feature map being used for the two feature maps
- Instead of having both feature maps use the more performant softmax-based feature map, it would be possible to have one softmax attention map and another use a linear attention map.
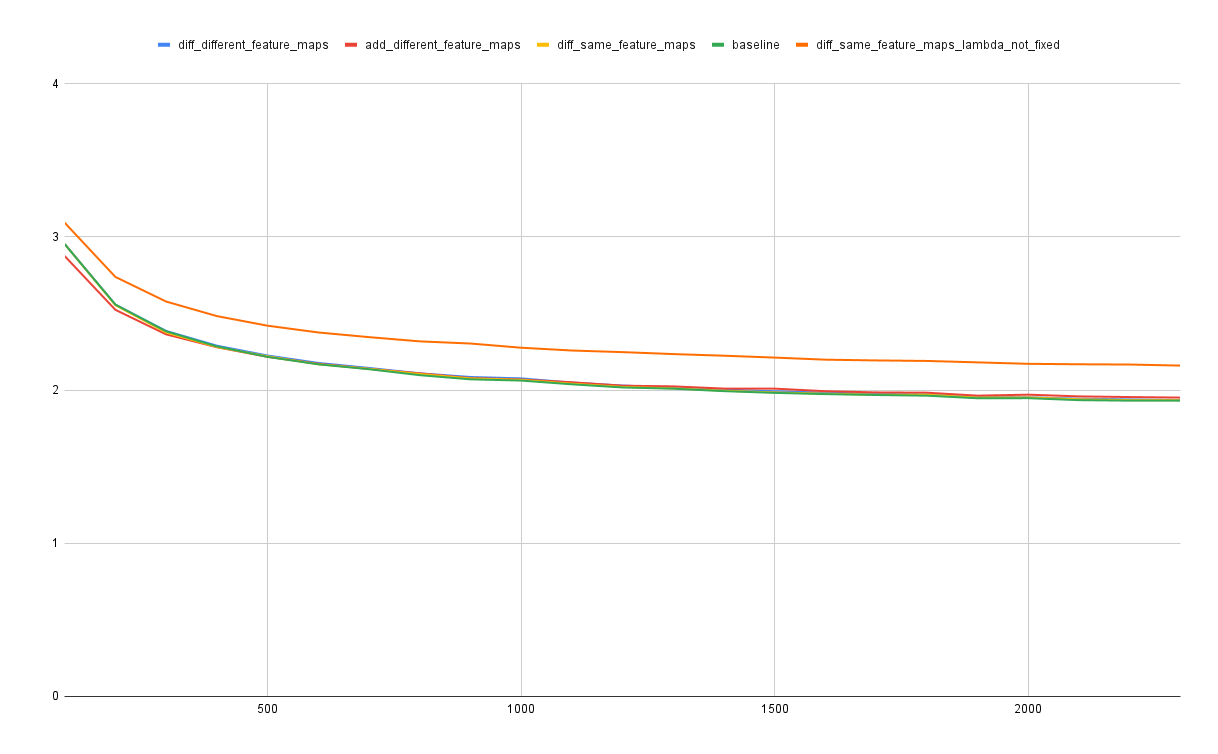
Results
The results show that none of these methods provides a significant improvement over using the original softmax-based feature map, when comparing the mean squared error of the fully computed attention using the feature-map and using softmax over the validation set.
Potential next steps
- Run the training step with PEFT afterwards to see if there is any difference in results.
- Try changing the feature map itself
- I briefly tried raising the power of the outputs in the softmax attention map to 3/2 to see if that would lead to anything, but it didn't improve performance whatsoever
- Use more layers in the feature mapping stage.
Thoughts on using AI
- I tried using o1 to help me figure out a way to include differences into the feature map. While the first equation (where the second feature map) was a valid solution to the problem of non-negativity, when I described the rest of the problem, there wasn't much in terms of valid solutions. It doesn't seem to be that great with more creative problems.
- When exploring a larger repository, context windows still provide a significant challenge to models. Right now, I'm using Copilot (as the subscription is free with my student account), but I'm looking forward to trying Windsurf soon.
- It's really helpful when it comes to catching typos or parts of my writing that aren't clear.
My code is available on GitHub, and I'd love to hear your feedback on how I could improve the project! I also used vdaita/mini-linearization for initial testing.